CPU vs GPU vs TPU
CPU vs GPU vs TPU

Introduction
While most deep learning engineers/enthusiasts focus on algorithms,
they often forget about the hardware they use for training/inference. If you
ask them why GPU/TPU is faster than a CPU, you'll often hear responses like
"GPUs are optimized for convolutions or GPUs can run more threads". While these statements
are true, they merely scratch the surface. In this post, we dig deeper into the hardware to explain what's happening.
I'm not a hardware pro by any means, but I feel this information is critical for all
AI enthusiasts.
💡
The main trade-off b/w the three pieces of hardware is b/w Latency andThroughput
CPU
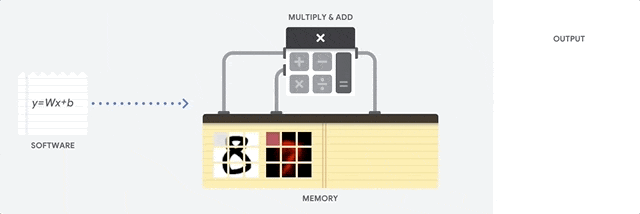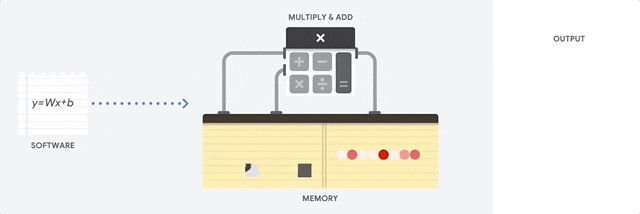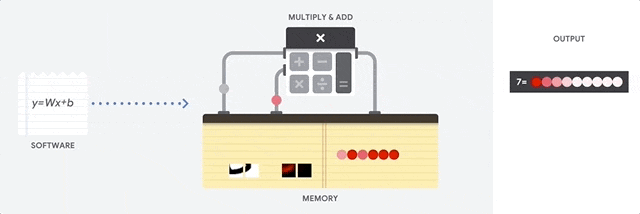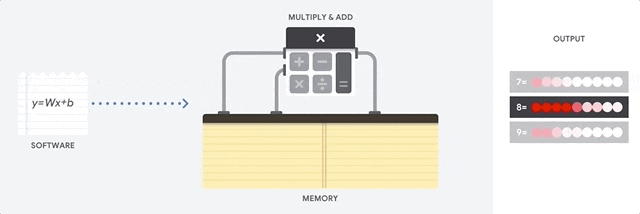
- CPUs are meant to be the most flexible piece of hardware, capable of running every software,
instruction by instruction - CPUs are not designed to only render graphics or multiply tensors, they need to load
databases, a variety of applications and run multiple threads where each thread is running a different instruction set. - To accomplish this, CPUs read instruction one by one from the memory, perform any
computation if needed, and write the result back into memory.
💡
CPUs optimize for latency over throughput
GPU

- GPUs are designed to process a single instruction simultaneously over a large
number of cuda cores. - Though the cores have lower clock speed, the sheer number of cuda cores is enough to crush CPU when it comes to tasks
like training deep learning models
💡
GPU optimizes for throughput over latency by running a large number of ALUs in parallel.But they are still general enough and support most of computations possible on a CPU.
TPU

- These MMUs are meant to avoid to memory access during a chain of tensor product operations. This is accomplished by a systolic array architecture.
💡
TPU are heavily optimized for ONLY deep learning tasks/operations, whilecompromising on the flexibility needed to perform other tasks.