Designing and shipping a ML Feature

What exactly are we trying to accomplish? Will the new model architecture really be a game-changer? How much impact will this new dataset have on the model accuracy?
These are some questions a typical machine learning team deals with on a daily basis.
But it is important to not get bogged down by the intricacies, and always go back to the first principles approach. With the pace at which new research papers are pouring in, it is important for ML/Data/CV Scientists to sometimes take a back seat and think about the overall picture a bit more.
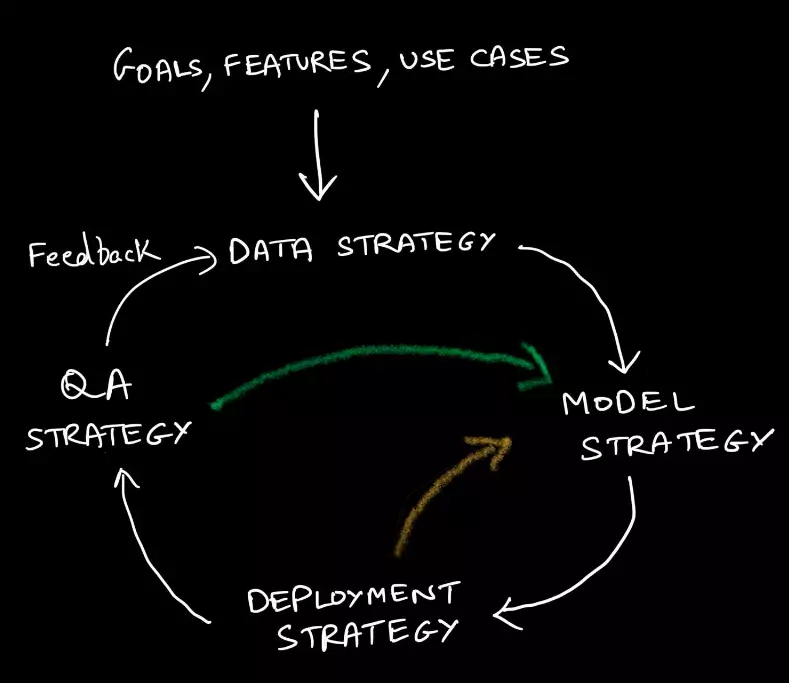
If we start off with a tiny open-source dataset and loop through this design cycle, we can establish a pretty solid baseline. The bulk of the work after this should be focused on the finer aspects of the product, the outliers/corner cases in particular.
Establishing goals and use-cases
This is perhaps the most important part of this strategy. It involves working closely with the product managers to decide the overarching goal, which dictates the key requirements of the product. Any mistake here can prove to be very costly, both from employee retention and a financial standpoint. After all, no one likes to work for managers who keep shifting the goal post.
Here are some key components of each strategy. I refrained from going into details for each component here, as it's mostly self-explanatory. Instead, I wanted to focus more on the vast breadth of issues here, since the finer details vary for each team.
Data Strategy
- Data Collection →Using "off the shelf" datasets or creating a dataset from scratch?
- Data Labeling →Manual or Automatic annotation?
- Data Backend →Storage, Indexing, and Delivery. Usually, AWS S3 is used for storage, while teams tend to build
their own layer (typically python-based) for serving the data.
Model Strategy
- Training Framework → Pytorch or Tensorflow?
- Training Infrastructure → AWS or self-built GPU rigs or both?
- "Off the shelf" models for establishing baseline (if available)
- Exploring the Accuracy / Speed TradeOff → This blog details how EfficientNet does exactly that.
- Neural architecture search → This blog talks about how NAS can be used in specific cases to greatly reduce the
network size while maintaining accuracy
Deployment Strategy
- On the cloud →Typically web apps are hosted on AWS, and the model will run in a multi-threaded manner on multiple GPU instances.
- On embedded device → Mobile phones, ASICS/FPGA, or other chipsets. While iPhones offer a painless experience in deploying ML models, android and other devices usually require more custom solutions, although that has started to change now.
- Model compatibility → This issue usually arises while deploying on embedded devices. Some ML ops may not be supported by the hardware, thus influencing the model strategy to accommodate the changes.
- Code consistency → This issue usually arises while deploying on embedded devices. If there's additional logic wrapping the model, it needs to be tested offline and online to ensure consistency.
- Speed Feedback → Quick prototyping may reveal some flaws in the model design causing latency issues. This influences the model strategy.
Quality Testing Strategy
- Right Metrics → Going back to the goal establishment phase, this is where we need to make sure the performance metrics mirror the goals.
- True fine-grained analysis → Qualitative and Quantitative analysis of the model is essential for iterative improvement. This impacts every strategy.
This is not an exhaustive list by any means, but many ML teams usually follow this model. Feel free to leave comments.