EfficientNet (V1 & V2) - A smart heuristic
EfficientNet tries to come up with a smart heuristic to scale a CNN, relating resolution, width, and depth of a CNN.

Intuition
EfficientNet tries to come up with a smart heuristic to scale a CNN, relating resolution, width, and depth of a CNN. In particular, it tries to
answer two key questions:
- What should be the best base network
- How to scale the base network(a) in an efficient manner
EfficientNet enables us to effectively control the compute used(FLOPs) by a network Vs accuracy. Moreover, it allows for fast inference on embedded devices.
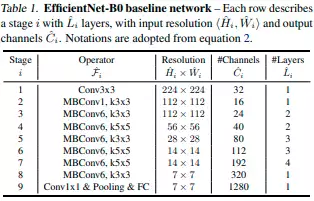
Finding the best base network
The author uses a multi-objective neural architecture search algorithm to
find a network (EfficientNet-B0). The objective function comprises of
Accuracy(x) * (Flops(x) / Target-Flops) as the target.
Scaling the base network
Now that the author has found the best network to scale, the question becomes how to relate resolution, width and depth of the network by one number,making it easier to scale.
The technique used in this paper tries to answer the following question:
How would you scale the network if you suddenly had twice as many resources ?
By trying different multiples of resolution, width, and depth of the network, the author lands on the multiples 1.15, 1.1, and 1.2 respectively. This means that if we scale the resolution, width, and depth of the network by the above-mentioned multiples, we will use twice as much compute compared to the base case when the multiples are 1 each. If we apply this approach in an incremental fashion, we will obtain optimized architectures which give high accuracy at the specified target flops.
UPDATE: EfficientNet V2
Some changes proposed in the latest architecture and methodology:
- Combination of Fused-MBConv and MB Conv instead of only MbConv
- Training-aware NAS - jointly optimizes for accuracy, parameter efficiency and training speed this time.
- Progressive Learning - Low regularization + small images initially during training, followed by high regularization
- large images later
- Small architecture changes.
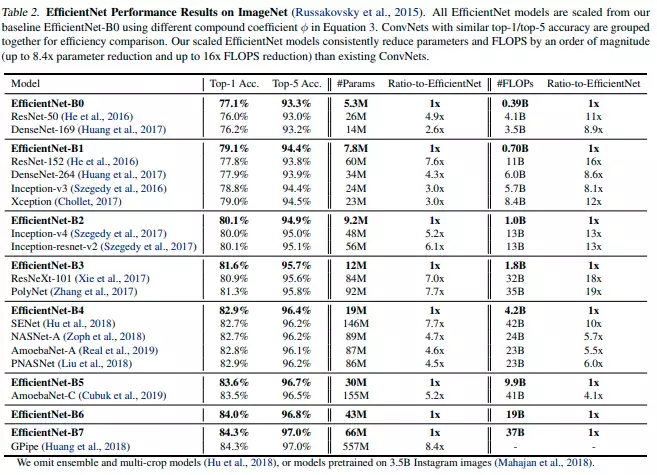
Results
References
- (https://arxiv.org/pdf/1905.11946.pdf) EfficientNet: Rethinking Model Scaling for CNNs - Mingxing Tan, Quoc V. Le