NOTES: Can LLMs truly reason?

Can LLMs actually reason, or are they just “probabilistic pattern matchers” ? This paper (GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models. by Mirzadeh et al.) attempts to answer that question.
Motivation:
- GSM8K benchmark is widely used to assess the mathematical reasoning of models on grade-school-level questions.

- While the performance of LLMs on GSM8K has significantly improved in recent years, it remains unclear whether their mathematical reasoning capabilities have genuinely advanced, raising questions about the reliability of the reported metrics.
Datasets:
- GSM-Symbolic: an enhanced benchmark that generates diverse variants of GSM8K questions using symbolic templates
- GSM-No Op: To create the templates, we add seemingly relevant but ultimately inconsequential statements to GSM-Symbolic templates. Since these statements carry no operational significance, we refer to them as "No-Op". These additions do not affect the reasoning required to solve the problem.
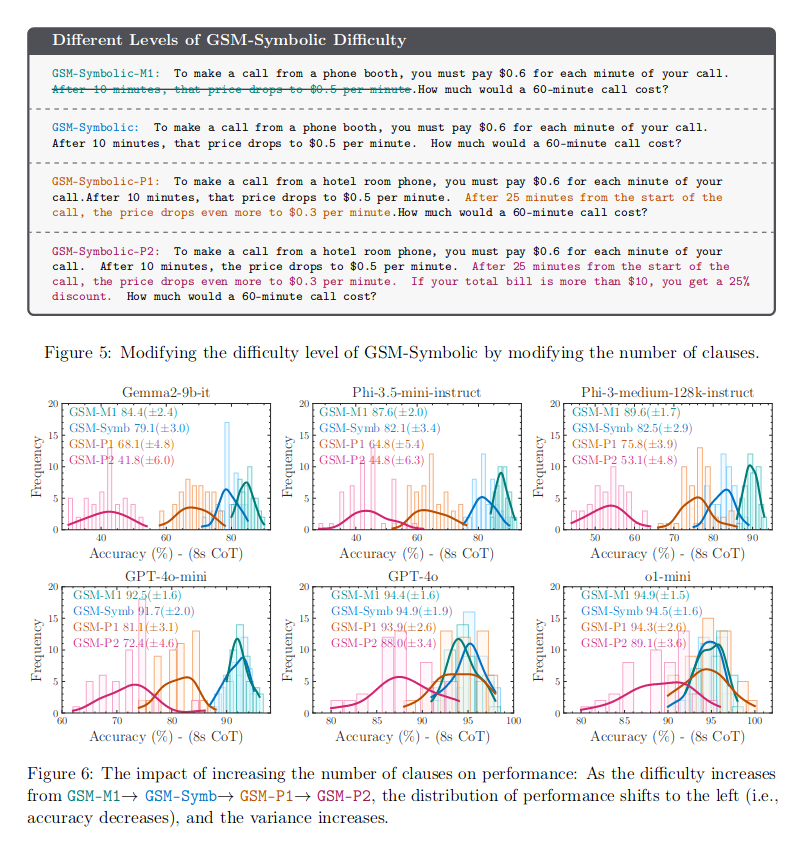
- GSM-Symbolic-{M1, P1, P2} : GSM-Symbolic with increasing difficulty M1 < P1 < P2
Findings:
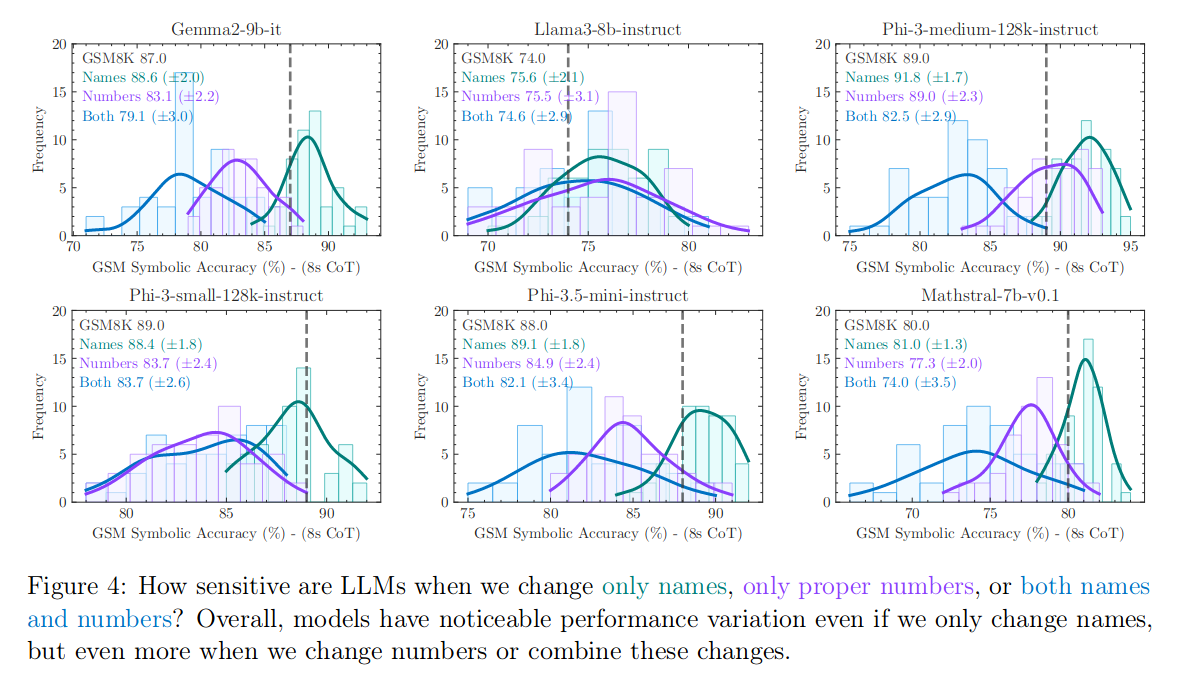
- LLMs exhibit noticeable variance when responding to different instantiations of the same question. Specifically, the performance of all models declines when only the numerical values in the question are altered in the GSM-Symbolic benchmark.
- When we add a single clause that appears relevant to the question, we observe significant performance drops (up to 65%) across all state-of-the-art models, even though the added clause does not contribute to the reasoning chain needed to reach the final answer.
- LLMs exhibit more robustness to changes in superficial elements like proper names but are very sensitive to changes in numerical values
- Results on GSM8K demonstrate that the performance of LLMs can be viewed as a distribution with unwarranted variance across different instantiations of the same question.
- By adding seemingly relevant but ultimately irrelevant information to problems, we demonstrate substantial performance drops (up to 65%) across all state-of-the-art models
- current LLMs are not capable of genuine logical reasoning; instead, they attempt to replicate the reasoning steps observed in their training data.
Techniques:
- Varying numbers, names or both in the GSM-Symbolic dataset to study the variance in responses.
- Adding additional constraints to the question, relevant or irrelevant, and studying the responses.
- Measuring the decrease in accuracy as the complexity of questions rises
Results:
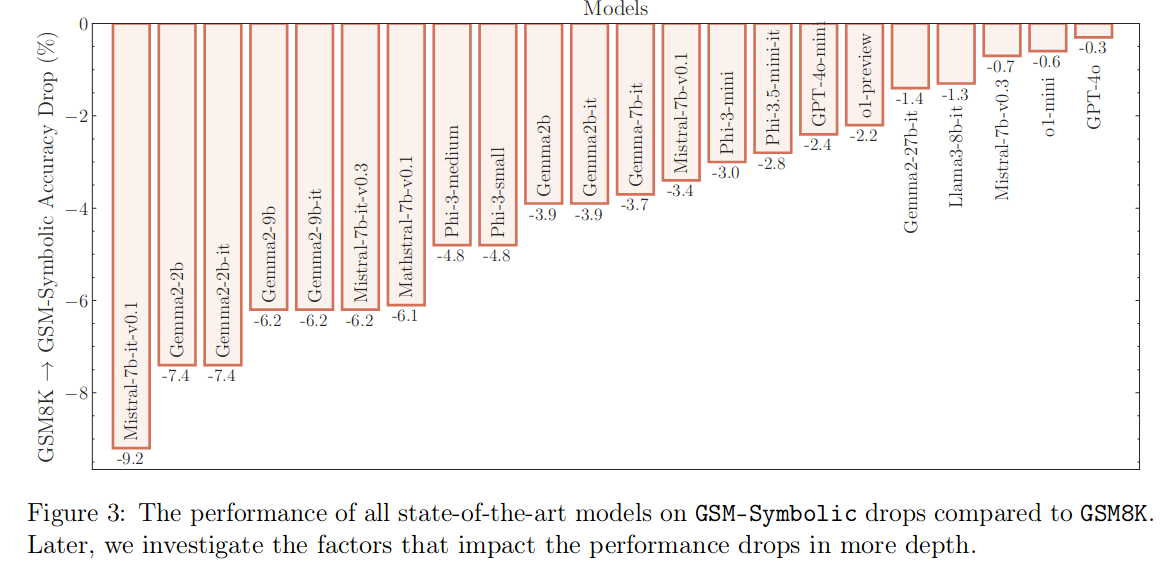
- Performance drop on GSM-Symbolic VS GSM8K. Most likely these models have memorized the results on GSM8K, since it has been publicly available for a long time
- Models are more robust to variations in Name, but less so for numbers.
- As the difficulty of questions increases, model performance reduces and variance in responses rises. This loosely suggests that the model can’t think logically.
- Models blindly infer certain operations, proving that they have memorized responses. In Both responses, models subtract the kiwis without being asked to do so.
