NOTES: Retrieval-Augmented Generation for Large Language Models
Here is a short compilation of bullet points gathered while reading the paper " Retrieval-Augmented Generation for Large Language Models: A Survey". The authors did a reasonably good job summarizing the landscape of current RAG systems.

Paper: Retrieval-Augmented Generation for Large Language Models: A Survey
Authors: Yunfan Gaoa, Yun Xiongb, Xinyu Gaob, Kangxiang Jiab, Jinliu Panb, Yuxi Bic, Yi Daia, Jiawei Suna, Meng Wangc, and Haofen Wang
Here is a short compilation of bullet points gathered while reading this paper. The authors did a reasonably good job summarizing the landscape of current RAG systems.
Notes
-
Retrieval-Augmented Generation (RAG) enhances LLMs by retrieving relevant document chunks from an external knowledge base through semantic similarity calculation.
-
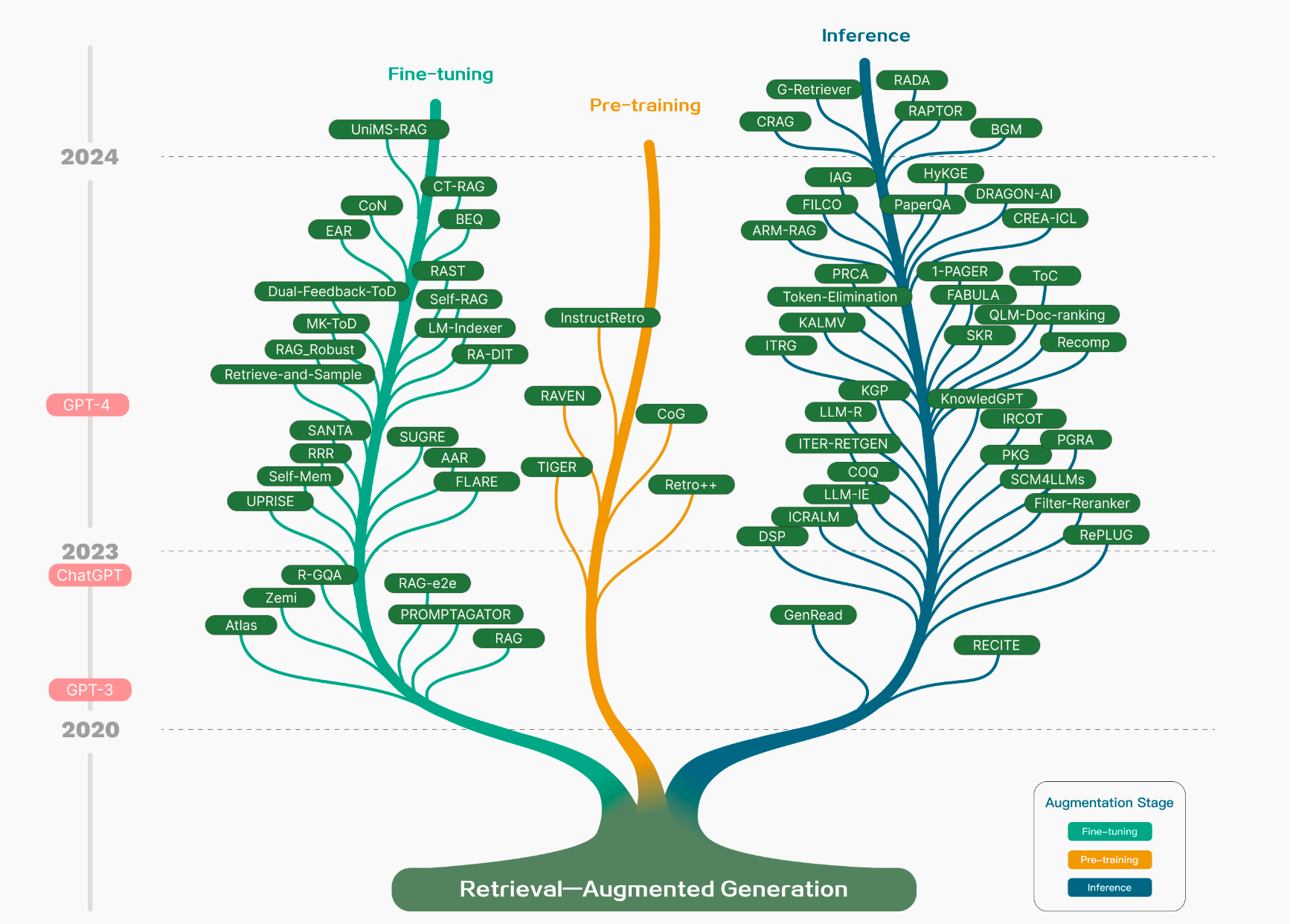
Development techniques:
- Pretraining LLMs
- Inference/ In-context learning
- Finetuning LLMs
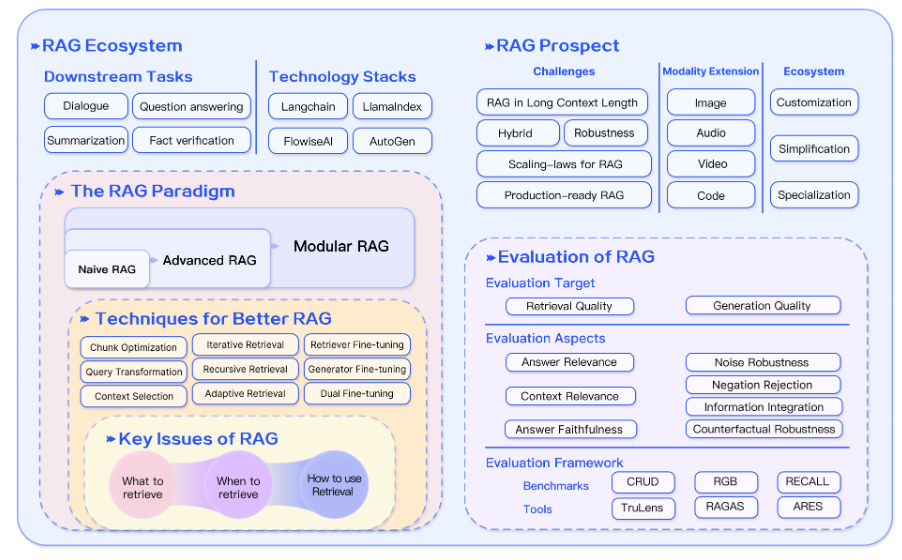
- Evolution of RAG:
- Naive
- advanced
- modular
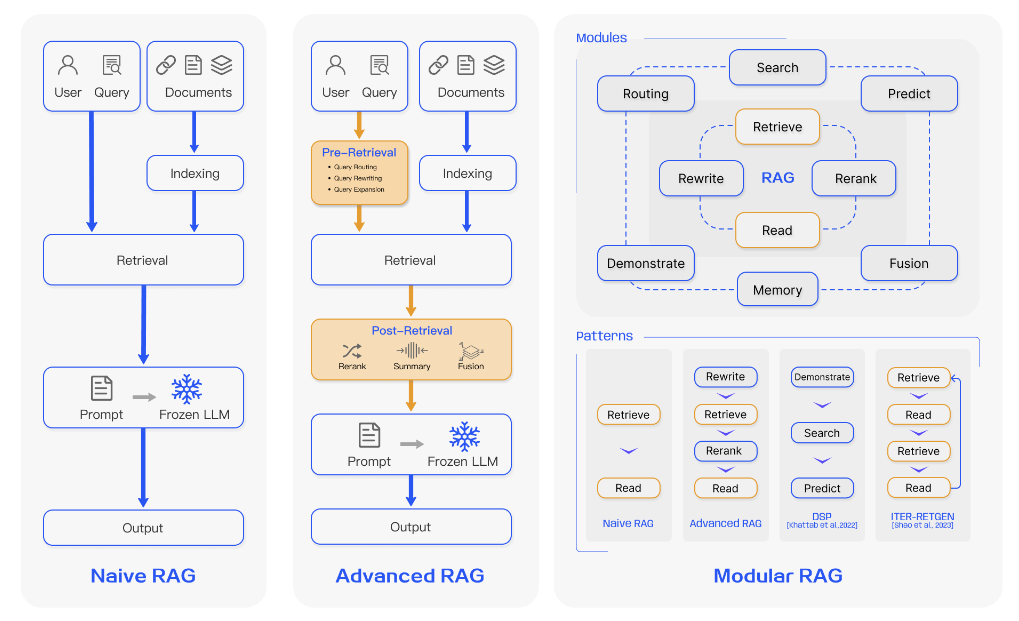
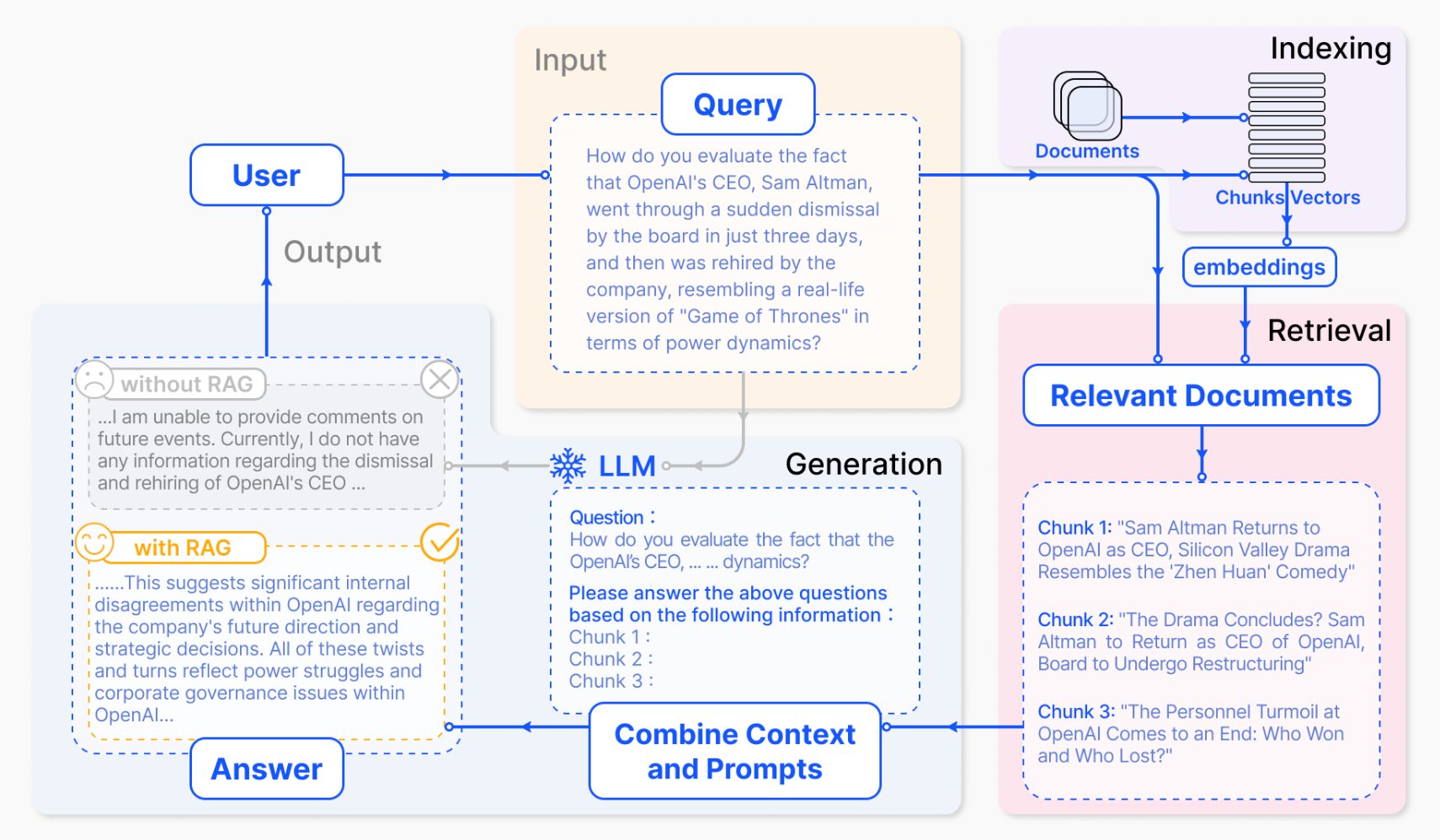
- Naive RAG
- 3 steps
- Indexing: Documents → chunks → vectors → Vector DBs
- Retrieval : Query → Vector → Semantic similar search → top K
- Generation : Query + top K vectors → Generated response
- Cons:
- imprecise retrievals: Irrelevant chunks
- too many similar chunks are retrieved leading to repeated responses
- 3 steps
- Advanced RAG
- Pre-retrieval and post-retrieval strategies
- Pre-retrieval
- enhancing data granularity, optimizing index structures, adding metadata, alignment optimization, and mixed retrieval.
- Query rewriting, query transformation
- Post-retrieval
- Feeding all relevant chunks can dilute key details with irrelevant content
- Reranking + context compression helps here
- Reranking retrieved information to the edges of the prompt is the key
- Pre-retrieval
- Pre-retrieval and post-retrieval strategies
- Modular RAG
- Multiple components more flexibility and adaptability as modules can be substituted depending upon task
- Numerous different patterns/strategies
- Types of modules:
- Search
- Fusion
- Memory
- Routing
- Predict
- Task adapter
- Types of strategies:
- Rewrite-Retrieve-Read
- Generate-Read
- Recite-Read
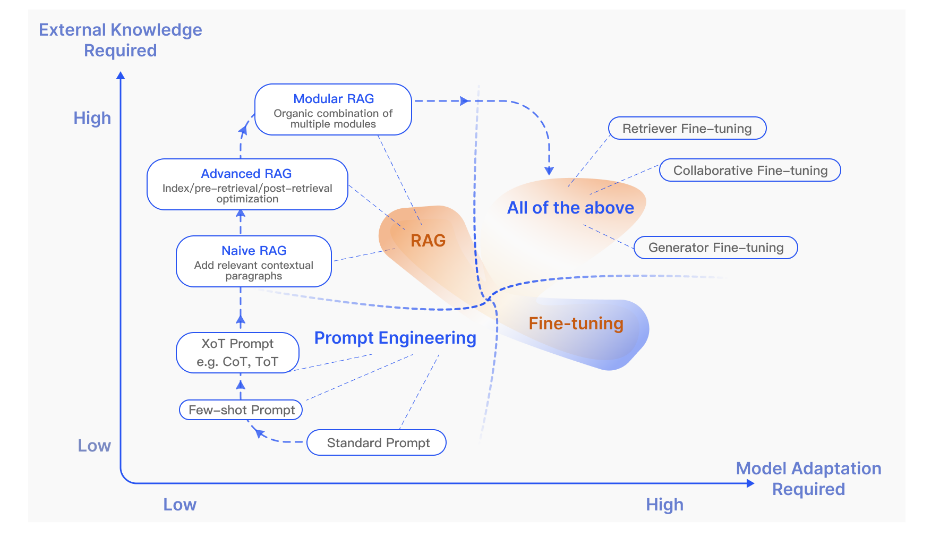
- RAG vs Fine-tuning
- RAG excels in dynamic environments by offering realtime knowledge updates and effective utilization of external knowledge sources with high interpretability. However, it comes with higher latency and ethical considerations regarding data retrieval.
- FT is more static, requiring retraining for updates but enabling deep customization of the model’s behavior and style. It demands significant computational resources for dataset preparation and training, and while it can reduce hallucinations, it may face challenges with unfamiliar data.
- While unsupervised fine-tuning shows some improvement, RAG consistently outperforms it, for both existing knowledge encountered during training and entirely new knowledge.
- LLMs struggle to learn new factual information through unsupervised fine-tuning, making a case for RAG
Retrieval
- Retrieval Source:
-
Data structures:
- Text
- Example: Wikipedia dump
- semi-structured data (PDF)
- text+table data
- Splitting text+tables is challenging
- semantic search with text+table is challenging
- structured data (Knowledge Graph, KG)
- More precise
- Need maintenance
- LLM generated
- Text
-
Retrieval granularity
- Coarse-grained retrieval units theoretically can provide more relevant information for the problem, but they may also contain redundant content, which could distract the retriever and language models in downstream tasks
- fine-grained retrieval unit granularity increases the burden of retrieval and does not guarantee semantic integrity and meeting the required knowledge.
- In text, retrieval granularity ranges from fine to coarse, including Token, Phrase, Sentences, Proposition, Chunks, Document. -
Indexing optimization
- documents will be processed, segmented, and transformed into Embeddings to be stored in a vector database.
- Chunking strategy
- most common method is to split the document into chunks on a fixed number of tokens (e.g., 100, 256, 512)
- Larger chunks can capture more context, but they also generate more noise, requiring longer processing time and higher costs.
- While smaller chunks may not fully convey the necessary context, they do have less noise.
- Metadata attachment
- page number, file name, author,category timestamp. Subsequently, retrieval can be filtered based on this metadata, limiting the scope of the retrieval.
- Assigning different weights to document timestamps during retrieval can achieve time-aware RAG, ensuring the freshness of knowledge and avoiding outdated information.
- HIerarchical + Knowledge graph index structure
- Data summaries are stored at each node, aiding in the swift traversal of data and assisting the RAG system in determining which chunks to extract. This approach can also mitigate the illusion caused by block extraction issues.
-
Query optimization
- Why is it important?
- Formulating a precise and clear question is difficult, and imprudent queries result in subpar retrieval effectiveness.
- Sometimes, the question itself is complex, and the language is not well-organized.
- Another difficulty lies in language complexity ambiguity. Language models often struggle when dealing with specialized vocabulary or ambiguous abbreviations with multiple meanings.
There are multiple techniques for query optimization, such as
- Query Expansion
- Expanding a single query into multiple queries enriches the content of the query, providing further context to address any lack of specific nuances, thereby ensuring the optimal relevance of the generated answers.
- Multi-Query: By employing prompt engineering to expand queries via LLMs, these queries can then be executed in parallel.
- Chain-of-Verification(CoVe): expanded queries undergo validation by LLM to achieve the effect of reducing hallucinations.
- Query Transformation
- Query rewrite
- The original queries are not always optimal for LLM retrieval, especially in real-world scenarios. Therefore, we can prompt LLM to rewrite the queries.
- RRR (Rewrite-retrieve-read)
- Query routing
- Routing different queries to different RAG pipelines
- Metadata router: based on metadata/keywords
- Semantic router: based on embeddings
- Query rewrite
- Why is it important?
-
Embeddings
retrieval is achieved by calculating the similarity (e.g. cosine similarity) between the embeddings of the question and document chunks, where the semantic representation capability of embedding models plays a key role.
- Most common: sparse encoder (BM25) and a dense retriever (BERT architecture Pre-training language models)
- Hugging Face’s MTEB leaderboard 7 evaluates embedding models across 8 tasks, covering 58 datasests.
- Hybrid retrieval: Use sparse and dense embedding models together.
- Fine-tuning embedding model:
- Needed when context significantly deviates from pre-training corpus, particularly within highly specialized disciplines such as healthcare, legal practice, etc
- another purpose of fine-tuning is to align the retriever and generator, for example, using the results of LLM as the supervision signal for fine-tuning, known as LSR (LM-supervised Retriever).
-
Adapter
Instead of fine-tuning the entire LLM, adapters are small trainable modules inserted between layers of LLM. These adapters undergo training, and improve the performance of the LLM on a target dataset.
-
Generation
- Context Curation
- Why?
- overly long contexts can also lead LLM to the “Lost in the middle” problem
- Like humans, LLM tends to only focus on the beginning and end of long texts, while forgetting the middle portion. Therefore, in the RAG system, we typically need to further process the retrieved content.- Reranking
- Reranking fundamentally reorders document chunks to highlight the most pertinent results first, effectively reducing the overall document pool, severing a dual purpose in information retrieval, acting as both an enhancer and a filter, delivering refined inputs for more precise language model processing
- rule-based methods that depend on predefined metrics like Diversity, Relevance, and MRR, or model-based approaches like Encoder-Decoder models from the BERT series, Cohere, GPT,etc
- Context Selection/Compression
- Models used to remove unimportant tokens
- Removing unimportant retrieved documents can be helpful too
- Another straightforward and effective approach involves having the LLM evaluate the retrieved content before generating the final answer.
- Reranking
- LLM Fine-tuning
- Targeted fine-tuning based on the scenario and data characteristics on LLMs can yield better results. This is also one of the greatest advantages of using on-premise LLMs. When LLMs lack data in a specific domain, additional knowledge can be provided to the LLM through fine-tuning.
- Alignment of responses:
- Aligning LLM outputs with human or retriever preferences through reinforcement learning
- For instance, manually annotating the final generated answers and then providing feedback through reinforcement learning
- Aligning LLM outputs with human or retriever preferences through reinforcement learning
- Why?
Augmentation
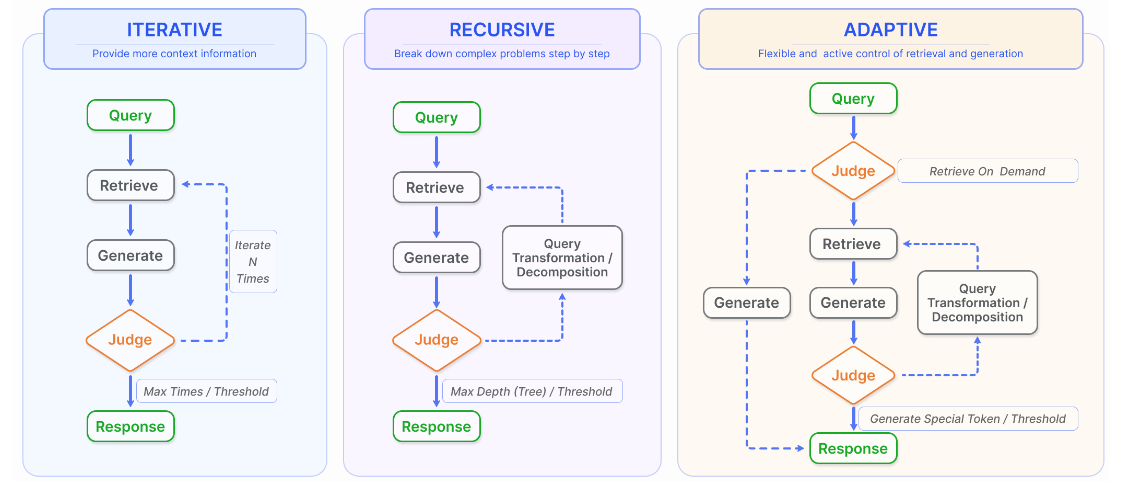
- Iterative retrieval
- Iterative retrieval is a process where the knowledge base is repeatedly searched based on the initial query and the text generated so far, providing a more comprehensive knowledge base for LLMs.
- Recursive retrieval
- Same as iterative rerieval, but the initial query is transformed/refined at each iteration
- gradually converging on the most pertinent information through a feedback loop.
- For example, IRCoT uses chain-of-thought to guide the retrieval process and refines the CoT with the obtained retrieval results.
- Adaptive retrieval
- LLMs decide whether external knowledge is needed or not
- Special tokens that facilitate actions such as web search, retrieve, critique, etc
- Thresholds around confidence of generated content also play a key role in the automation.
Evaluation
- Downstream tasks
- Question Answering (QA), including traditional single-hop/multi-hop QA, multiplechoice, domain-specific QA as well as long-form scenarios suitable for RAG.
- Information Extraction (IE), dialogue generation, code search
- Evaluation Metrics
- QA
- EM and F1 scores
- Answer quality
- BLEU and ROUGE metrics
- Retrieval quality
- Hit Rate, MRR, and NDCG
- QA
- Evaluation aspects
- Quality:
- Context Relevance
- Answer Faithfulness
- Answer Relevance
- Ability:
- Noise robustness: ignoring/distinguishing noisy/irrelevant retrieved documents from relevant ones
- Negative rejection: refraining from responding when retrieved documents are irrelevant
- information integration: synthesizing info from multiple docs
- counterfactual robustness: disregard known inaccuracies within fetched docs
- Quality:
- Benchmarks
- RGB
- RECALL
- CRUD
- Question Answering (QA), including traditional single-hop/multi-hop QA, multiplechoice, domain-specific QA as well as long-form scenarios suitable for RAG.
Discussion and future prospects
- RAG vs Long Context
- Is rag still needed when LLMs can consume context of up to 200k tokens?
- RAG-based generation can quickly locate the original references for LLMs to help users verify the generated answers
- The entire retrieval and reasoning process is observable, while generation solely relying on long context remains a black box.
- the expansion of context provides new opportunities for the development of RAG, enabling it to address more complex problems and integrative or summary questions that require reading a large amount of material to answer
- Is rag still needed when LLMs can consume context of up to 200k tokens?
- Hybrid approach
- Combining RAG with fine-tuning is emerging as a leading strategy.
- Existing tools and frameworks
- Langchain. Llamaindex
- Flowise AI, Haystack, Meltano, Cohere
- Weviate, Kendra (Amazon)
Summary
Simple RAG Pipeline using Langchain
import getpass
import os
os.environ["HUGGINGFACEHUB_API_TOKEN"] = getpass.getpass("Enter your token: ")
from langchain_huggingface import HuggingFaceEndpoint
# Using a huggingface model here instead of OPENAI, since it's free and open-source
llm = HuggingFaceEndpoint(
repo_id="HuggingFaceH4/zephyr-7b-beta",
task="text-generation",
max_new_tokens=512,
do_sample=False,
repetition_penalty=1.03,
)
The token has not been saved to the git credentials helper. Pass `add_to_git_credential=True` in this function directly or `--add-to-git-credential` if using via `huggingface-cli` if you want to set the git credential as well.
Token is valid (permission: read).
Your token has been saved to /home/kunal/.cache/huggingface/token
Login successful
Load blog
import bs4
from langchain import hub
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load, chunk and index the contents of the blog. Uinsg my own blog here for simplicity
loader = WebBaseLoader(
web_paths=("https://www.clearsignal.xyz/cpu-vs-gpu-vs-tpu/",))
docs = loader.load()
model_name = "BAAI/bge-base-en-v1.5"
model_kwargs = {"device":'cpu'}
encode_kwargs = {'normalize_embeddings':True}
hf = HuggingFaceEmbeddings(
model_name = model_name,
model_kwargs = model_kwargs,
encode_kwargs = encode_kwargs
)
Setup vector Store
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=hf)
Setup Retreiver
from loguru import logger
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6})
# Example
retrieved_docs = retriever.invoke("What are the approaches to Task Decomposition?")
logger.info(f"Number of retrieved docs: {len(retrieved_docs)}")
logger.info(f"Content of first doc: {retrieved_docs[0].page_content}")
[32m2024-09-24 15:09:46.683[0m | [1mINFO [0m | [36m__main__[0m:[36m<module>[0m:[36m7[0m - [1mNumber of retrieved docs: 6[0m
[32m2024-09-24 15:09:46.684[0m | [1mINFO [0m | [36m__main__[0m:[36m<module>[0m:[36m8[0m - [1mContent of first doc: Fig. 1. Overview of a LLM-powered autonomous agent system.
Component One: Planning#
A complicated task usually involves many steps. An agent needs to know what they are and plan ahead.
Task Decomposition#
Chain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.[0m
Setup Prompt and chain
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
/home/kunal/work/miniconda3/envs/torch/lib/python3.8/site-packages/langsmith/client.py:323: LangSmithMissingAPIKeyWarning: API key must be provided when using hosted LangSmith API
warnings.warn(
Invoke Prompt
rag_chain.invoke("How does a GPU work?")
' A GPU (graphics processing unit) works by processing a large number of computations simultaneously, specifically designed for tasks such as rendering graphics and performing matrix operations. It is optimized for throughput over latency by running a large number of ALUs (arithmetic logic units) in parallel. This design allows GPUs to excel at tasks such as training deep learning models due to the high computational demands required. TPUs (tensor processing units) are a specialized type of processor designed specifically for machine learning and deep learning tasks. They are heavily optimized for ONLY these types of operations, compromising on the flexibility needed to perform other tasks. While CPUs (central processing units) can also perform these tasks, they are not optimized specifically for them, and their design requires them to execute instructions sequentially, making them less efficient for these tasks. In summary, CPUs are better suited for general-purpose computing, while GPUs and TPUs are better for specific computing tasks such as graphics rendering and machine learning.'