Short NLP Overview!
**Natural language processing (NLP)** is a branch of science sitting at the intersection of computer science, artificial intelligence, and computational linguistics. To put it simply, it gives computers the ability to read, understand and generate text and speech just like we do

Outline
Introduction
Natural language processing (NLP) is a branch of science sitting at the intersection of computer science, artificial intelligence, and computational linguistics. To put it simply, it gives computers the ability to read, understand and generate text and speech just like we do. Within the last decade, NLP-based products have become ubiquitous. Here are some common
NLP applications/products you might be aware of:
- Amazon Alexa or Siri
- Voice input in Google or Apple Maps
- Conversational chatbots
- Google or Siri Translate
From a computer vision scientist's perspective, NLP is becoming increasingly important as time goes by. From the use of pre-trained embeddings to vision transformers, we are starting to observe how architectures used in both fields have concepts in common. For all aspiring AI practitioners, it is important to know the basic algorithms in
both fields.

NLP can be broadly broken down into 4 key areas:
- Language Modeling
Language modeling is the task of assigning a probability to sentences in a language. Besides assigning a probability to each sequence of words, the language model also assigns a probability for the likelihood of a given
word (or a sequence of words) to follow another sequence of words. [1] - Morphology
Morphology is the study of words, how they are formed, and their relationship to other words in the same language. It analyzes the structure of words and parts of words such as stems, root words, prefixes, and suffixes. [2] - Parsing / Syntactic Analysis
Syntactic analysis, also referred to as syntax analysis or parsing, is the process of analyzing natural language with the rules of formal grammar. Grammatical rules are applied to categories and groups of words, not individual words, thereby assigning a semantic structure to text. [3] - Semantic Analysis
Semantic analysis refers to the process of understanding the meaning behind sentences. it is a study of what words mean when they are put together in a sentence. It takes into account the individual meaning of words, how they relate and modifies neighboring words, and the context these words appear in.
Neural Network Modeling
Modern-day NLP mostly relies on deep neural networks(DNN) for predictions. NLP engineers have to make 3 important choices before they train any neural network:
- Defining the "Task"
- Choosing word embeddings
- Choosing the neural network architecture
Defining the "Task"
Here are some broad categories defined in the AllenNLP model library. Code + paper + weights are available at Papers with Code website.
a. Classification: Predicting one or more labels for each input. For example Sentiment analysis
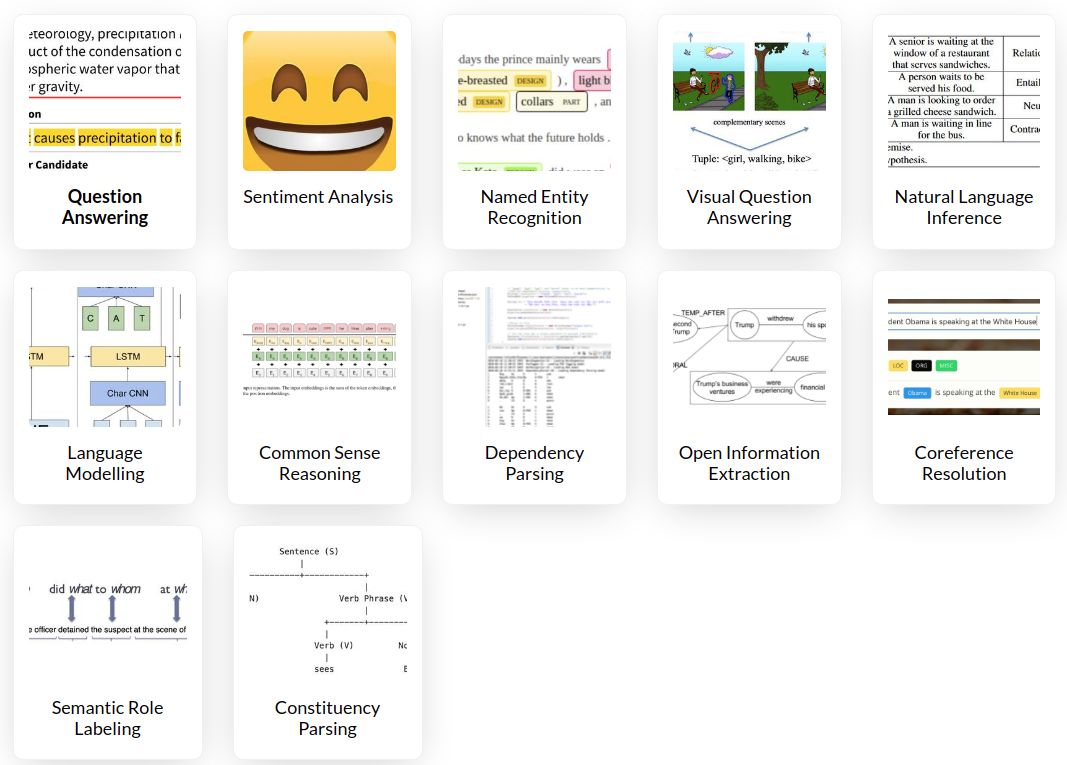
b. Coreference Resolution: The goal is to find all expressions that are related to the same entity.
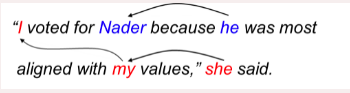
c. Generation: Generating unstructured text of variable length. For example GPT-3
d. Language Modeling: Learning a probability distribution over a sequence of tokens.
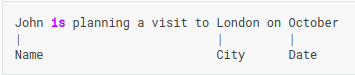
e. Sequence Tagging: Information extraction task where each word in a sentence is classified with a pre-defined label set.
PS: This is not an exhaustive list.
Choosing word embeddings
NLP deals with massive vocabularies, ranging from 100k to millions of words. It would be inefficient to train a network if each word is represented with a vector of size V (where V is the size of this vocabulary). Word embeddings solve this problem as they reduce the dimensions of the encoding (compared to V), while adding meaning to the vectors.
Here are some common word embeddings:
-
Embedding Layer
This is a neural network layer with weight dimensions (V x N), where V is the size of the vocabulary, and N is the embedding dimension. It is initialized with random values and the word embeddings are learned during the training phase. [Detailed Explanation] -
Word2Vec
Word2Vec was developed by Mikolov et al. paper in 2013. This technique uses the
local context around a word to develop a meaningful representation of it. It has two flavors:- Continuous Bag Of Words Model
- Skip-gram Model
More details can be found here
-
GloVe (Global Vectors for Word Representation)
GloVe was developed by Manning et al. At Stanford University. The main intuition underlying the model is the simple observation that ratios of word-word co-occurrence probabilities have the potential for encoding some form of meaning.
More details can be found here -
ELMO (Embeddings from Language Models)
All the embeddings discussed above aim to provide 1 embedding per word, but we know that the meaning of a word changes with context.
To solve this problem, ELMO trains custom deep embeddings for each word, based on the context/usage. For example, the word "right"
will have different embeddings for the following sentences:- Take the next right.
- You are right about that problem.
-
BERT (Bidirectional Encoder Representations from Transformers)
Both Elmo and Bert are deep embeddings that involve training wider/deeper neural networks on a big corpus.
The key difference between the two lies in the training objective.- ELMO uses the traditional Language Modeling training objective to generate the next word given previous words in the sentence. It tries to calculate P(Xi| Xi-1, Xi-2, Xi-n) such that the resulting distribution mimics the distribution in the training corpus.
- Bert uses the 'masked' language modeling objective. It randomly masks words (with some probability) in the training corpus and uses the surrounding words to predict the missing word.
Choosing the neural network architecture
There are two classes of architectures we should look at:
Traditional Sequence models
The most commonly used sequence models are :
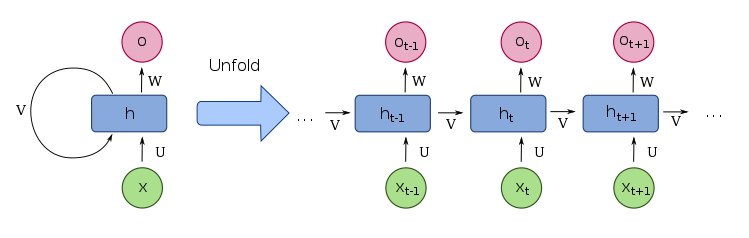
a. RNN (Recurrent neural networks)
Recurrent neural networks are a class of networks that consume sequential inputs. They update the current state(memory) based on the previous state and the current input.
{kind=link}
b. LSTM (Long short term memory) networks
LSTM is a type of RNN that gets rid of the vanishing gradient problem by regulating the gradient flow using gates.
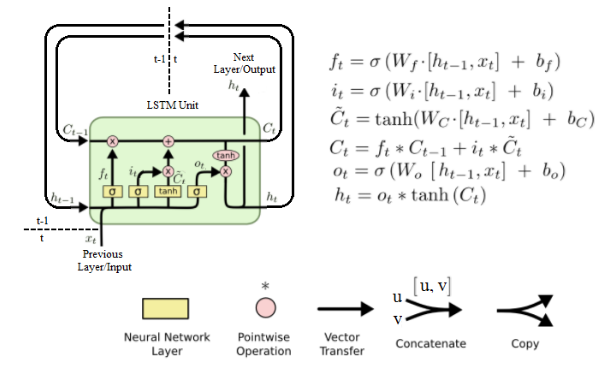
c. GRU (Gated recurrent unit) networks
GRU is a simplified version of LSTM, with only 2 gates instead of 3. It's faster to train as compared to LSTMs and provides similar performance metrics on a variety of datasets.
NOTE: A step by step explanation on these models can be found at Colah's Blog.
Transformers
Transformer networks are one of the most widely used architectures in NLP over the last 4 years. The architecture deploys a novel use of the familiar concepts of self-attention, multi-head attention, and positional encodings inside an encoder-decoder design, thereby enhancing the performance of the model. GPT-3 uses a modified version of this architecture and almost passed the Turing test for short articles!
Please refer to this blog for more details on transformers.
Available Resources
Paid APIs for NLP
The API industry for NLP has really blossomed over the years. You can find APIs for all the tasks listed here.
Here are a few APIs that I came across:
- Google Cloud
- HuggingFace
- NLP Cloud
- IBM Watson
- Aylien
Python Libraries for NLP
I've been experimenting with AllenNLP, which provides pre-built models, encoder/decoder blocks, vocabulary builders, indexers, and tokenizers. It's a layer on top of Pytorch and seems pretty intuitive. Moreover, the documentation provided is sufficient to get started with, which isn't the case with TorchText as of now. Other than that, they don't differ a lot.
Here are some open-source python libraries which can be used for model training and inference:
- TorchText : Torch Library
- Spacy : This is equivalent to 'scipy' for NLP !
- HuggingFace: primarily used for transformers, sharing open-source models, datasets and metrics
- AllenNLP: research framework built on pytorch
This concludes this short intro to NLP. I'll try to snipe at certain topics and provide a detailed analysis in the upcoming articles.
Thanks for reading!