Semantic Segmentation - DeepLab V3+

Semantic Segmentation
Semantic segmentation involves partitioning/marking regions in the image
belonging to different objects/classes. Deep learning methods have made a remarkable
improvement in this field within the past few years. This short article summarises
DeepLab V3+, an elegant extension of DeepLab v3 proposed by the same authors (Chen et al.).
Intuition
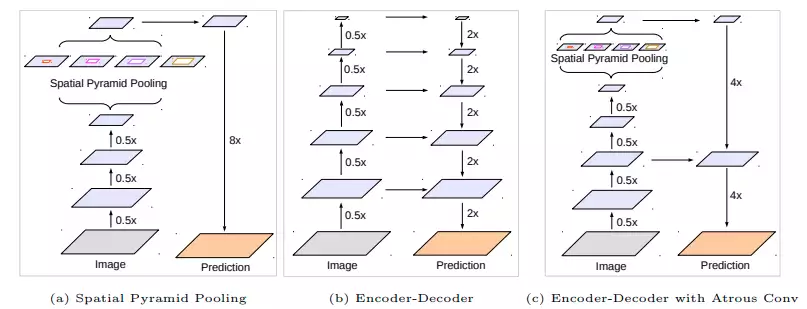
Previously, ASPP (Atrous Spatial Pyramid Pooling) has been used to extract rich multi-scale features from images. The authors of Deeplab v3+ try to combine the ASPP module with the good old encoder-decoder architecture with skip connections, thereby providing better details in predictions.
Architecture
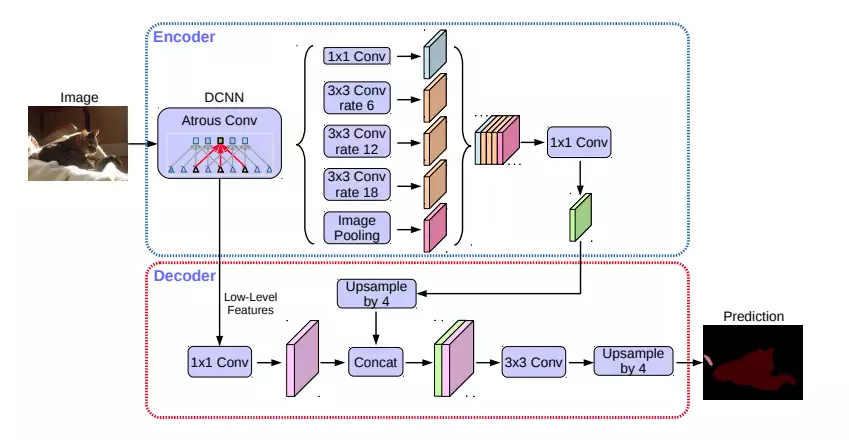
Here are the key features of this architecture:
- Atrous Depthwise Convolution: The depthwise convolution has an added dilation to make it atrous.
- ASPP style encoder from DeepLab V3 + UNet style decoder with skip connections.
- Modified Xception network as the backbone: This can be replaced by any backbone; HRNet seems to be widely used these days.
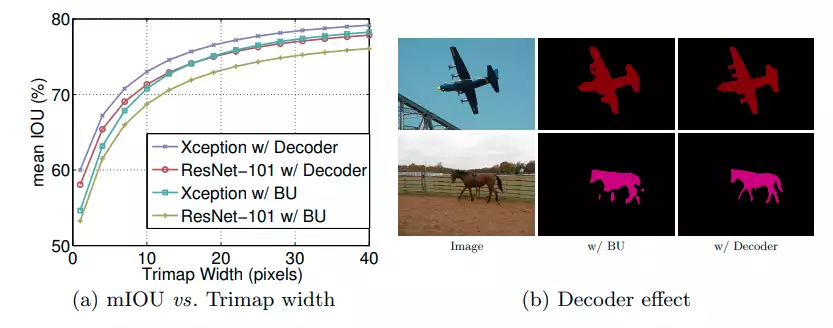
Results
References
- (https://arxiv.org/pdf/1802.02611.pdf) Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
- (https://arxiv.org/abs/1610.02357) Xception: Deep Learning with Depthwise Separable Convolutions
- (https://arxiv.org/pdf/1606.00915v2.pdf) DeepLab: Semantic Image Segmentation with
Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs - (https://arxiv.org/abs/1801.04381) MobileNetV2: Inverted Residuals and Linear Bottlenecks