Yolo-X Notes
The main motivation behind YOLOX was to update the YOLO series with the recent advancements at the time, particularly anchor-free detection.

Motivation
- The main motivation behind YOLOX was to update the YOLO series with the recent advancements at the time, particularly anchor-free detection.
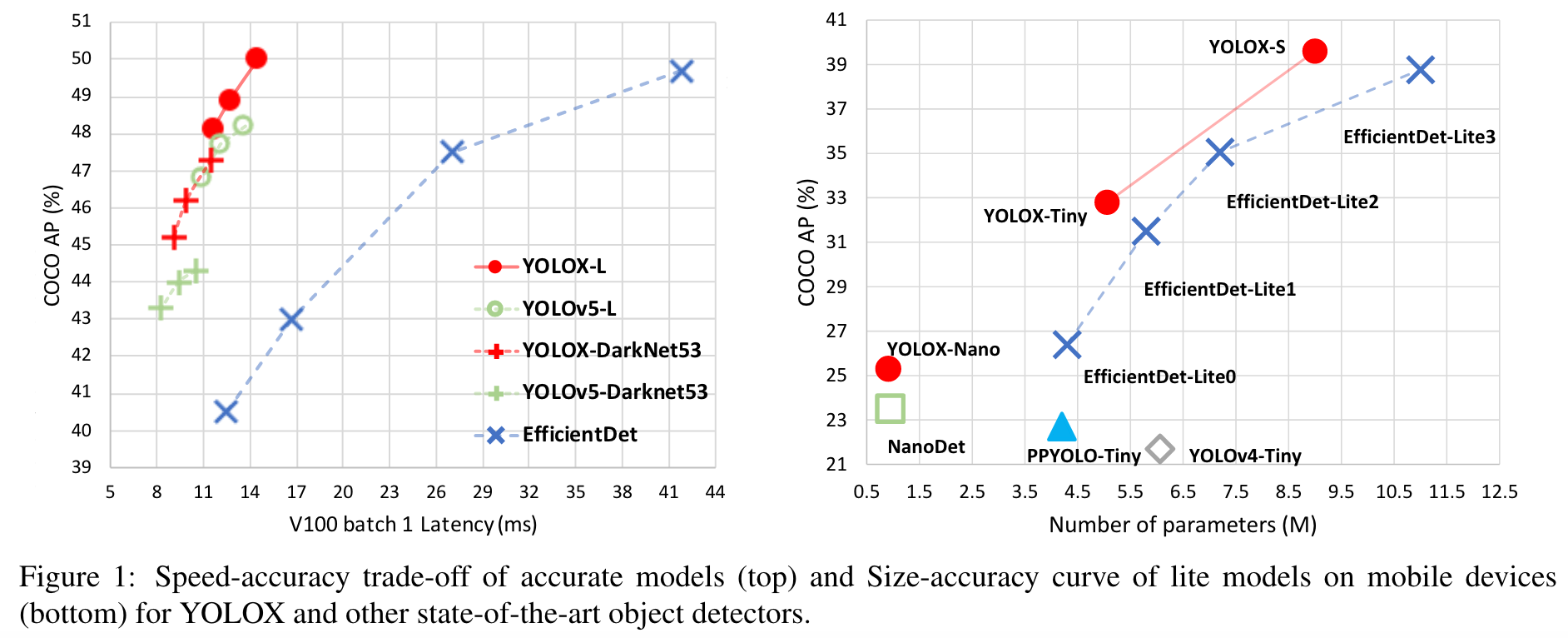
- When YoloX came out in 2021, YOLOv5 held the best trade-off performance with 48.2% AP on COCO at 13.7 ms. This inference time was calculated using YOLOv5-L model at 640 × 640 resolution with FP16-precision and batch=1 on a V100.
- YOLOv4 and YOLOv5 still used anchor-based detectors with hand-crafted assigning rules for training.
Novelty
This paper chose Yolov3 as the baseline and added incremental improvements to it, such as:
- Anchor free detection
- Eliminates the need for clustering analysis to determine optimal anchor sizes. Such anchors are domain-specific and less generalized.
- Anchors increase complexity in two ways. Firstly, the number of predictions from the detection heads is too high. This can cause potential memory bottlenecks. Secondly, anchors are associated with several tightly tuned design parameters, making decoding harder.
The anchor-free concept appears to have been adapted from the FCOS paper.
- SimOTA label assignment
YoloX adopts a simplified version of the label assignment strategy created by the same authors in the OTA paper. Labels are matched to the predictions based on a cost value (weighted sum of losses). Then an IOU is calculated relative to the sampled center (center-sampling from FCOS) to determine the top k matches, also known as the Dynamic-k strategy.
- Strong augmentation - Mosaic and Mixup
Strong augmentation ensures that pre-training with Imagenet is no longer beneficial. Models are trained from scratch with this augmentation.
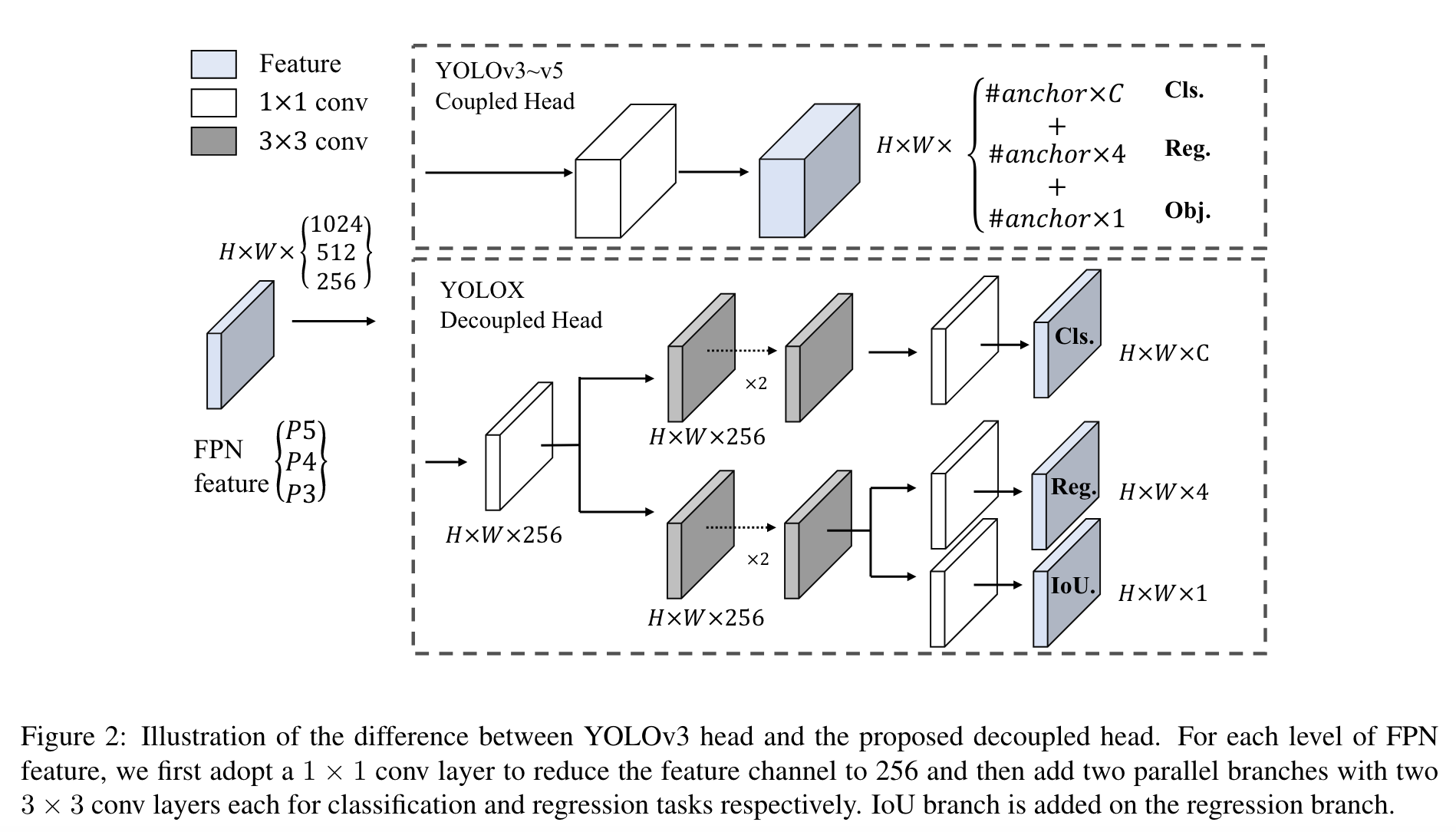
- Decoupled head for classification and regression
- Improves convergence speed
- Improves AP
Results
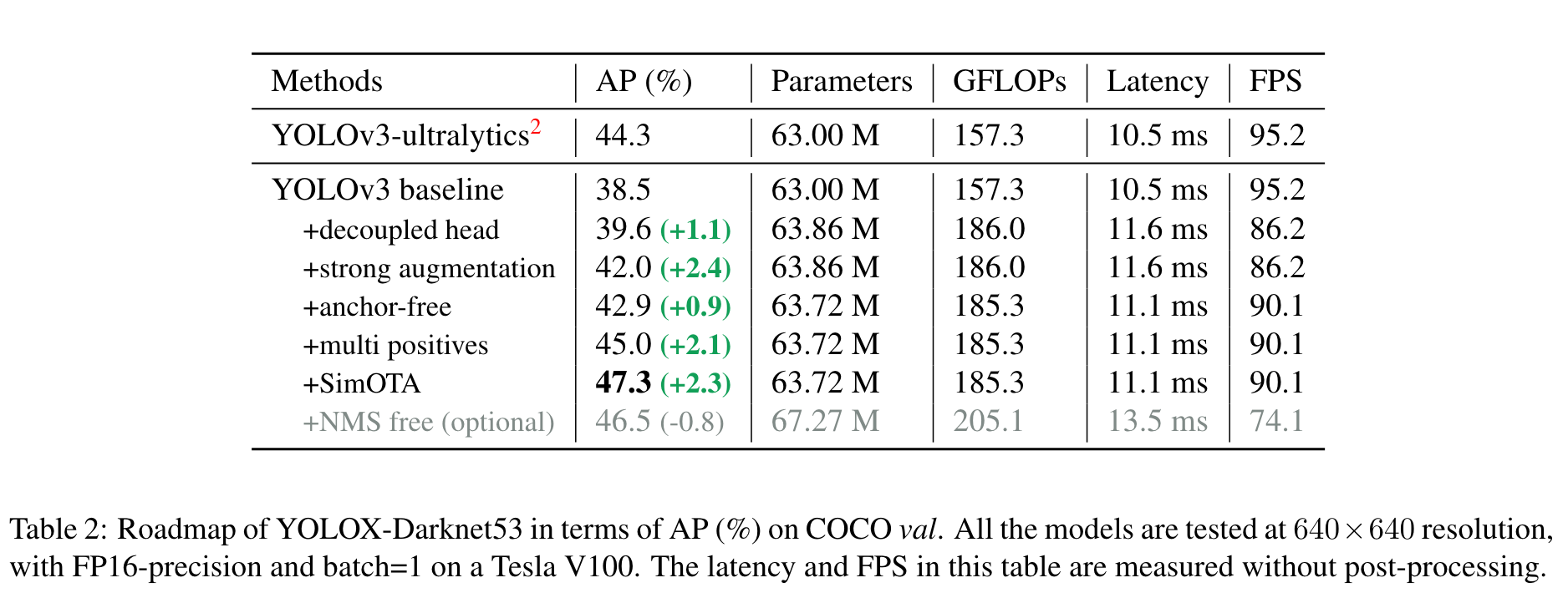
- Baseline: Beats YoloV3 baseline by 3% mAP on Coco when using the same backbone (DarkNet53)
- Large model (YOLOX-L): Beats YoloV5-L baseline by 1.8% mAP on Coco when using the same backbone and other enhancements (CSPNet and additional Pan head)
- Small model (YOLOX-Tiny): Beats YoloV4-Tiny baseline by 10% mAP on Coco when using the same backbone and other enhancements